
In machine learning, the effectiveness of a model is significantly influenced by the hyperparameters selected during its training process. Optimizing these hyperparameters is essential for enhancing a model’s performance and efficiency. If you’re currently taking a data science course or considering a data science course in Mumbai, mastering the techniques for hyperparameter tuning is key to improving your machine learning models. Two of the most popular methods for tuning hyperparameters are Grid Search and Random Search. Each method provides a different approach to identifying the best hyperparameter combination, and knowing the distinctions between them will help you choose the right one for your project.
What Are Hyperparameters?
Hyperparameters are the configurations set before a model’s training begins. Unlike model parameters, which are learned during training, hyperparameters control the training process. They can significantly influence how well the model performs on unseen data. Hyperparameters often consist of elements like the learning rate, the depth of layers in a neural network, and the count of trees in a random forest model. Hyperparameter tuning aims to find the optimal combination of these values, leading to the highest model performance.
Why is Hyperparameter Tuning Important?
Hyperparameter tuning is vital because it can dramatically improve a model’s performance. For example, if the learning rate is too high or too low, the model may fail to converge or learn too slowly. Similarly, choosing the correct depth or number of trees in decision tree algorithms can lead to better predictions or avoid overfitting. A data scientist can achieve the best balance between accuracy, speed, and generalization by optimizing these settings.
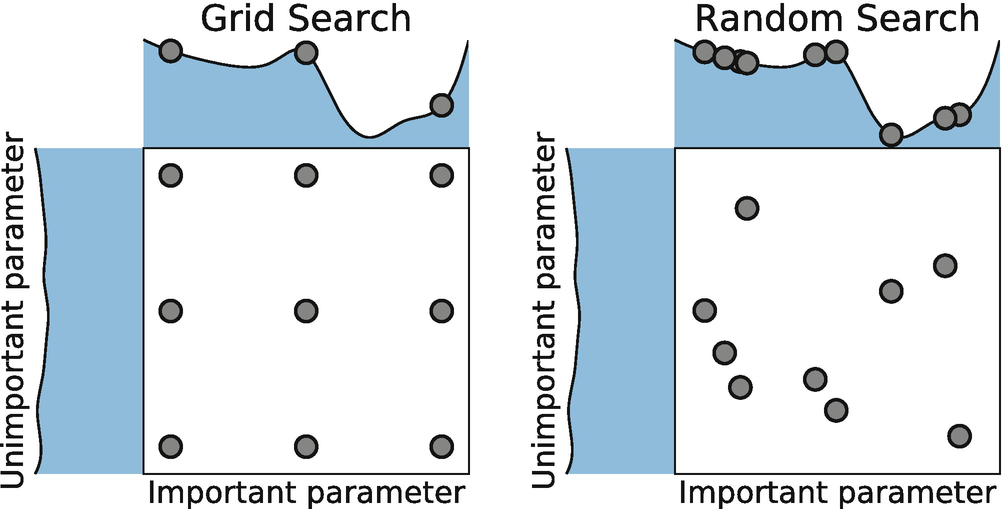
What is Grid Search?
Grid Search is one of the most straightforward and comprehensive methods for hyperparameter tuning. It systematically evaluates all possible combinations of hyperparameters within a predefined search space.
How Grid Search Works
In Grid Search, you define a set of hyperparameters and their possible values. The algorithm then exhaustively checks every possible combination of these hyperparameters to determine which set produces the best results. For example, if you are tuning a model with two hyperparameters – learning rate and the number of trees in a random forest – you might define the following ranges:
- Learning rate: [0.001, 0.01, 0.1]
- Number of trees: [50, 100, 150]
Grid Search will then evaluate all nine combinations: (0.001, 50), (0.001, 100), (0.001, 150), (0.01, 50), and so on until all combinations are tested.
Advantages of Grid Search
- Comprehensive: Grid Search guarantees that every possible combination of the chosen hyperparameters will be tested, so there’s no possibility of missing the optimal set.
- Simple to Implement: The method is easy to understand and apply, making it a great starting point for beginners in machine learning.
- Works Well for Small Datasets: Grid search can be very effective if the dataset is small and the hyperparameter space isn’t too large.
Disadvantages of Grid Search
- Computationally Expensive: Grid Search can be very time-consuming, especially when there are many hyperparameters, each with multiple possible values.
- Inefficient for Large Datasets: As the number of hyperparameters rises, the total combinations increase exponentially, making Grid Search less feasible for more complex models.
- Limited by Search Space: If you don’t define the search space well, Grid Search might miss the optimal values outside the predefined grid.
What is Random Search?
Random Search is another technique used for hyperparameter tuning, and it works quite differently from Grid Search. Instead of exhaustively testing all combinations of hyperparameters, Random Search randomly samples from the search space.
How Random Search Works
In Random Search, you specify a range of values for each hyperparameter, and the algorithm selects random combinations of these values to test. For example, you could define a range of values for the learning rate and the number of trees in a random forest:
- Learning rate: [0.001, 0.01, 0.1]
- Number of trees: [50, 100, 150]
Instead of testing all possible combinations like Grid Search, Random Search might test (0.01, 50), (0.1, 150), or (0.001, 100) at random, and it repeats this process until a predetermined number of evaluations are made.
Advantages of Random Search
- Efficiency: Random Search is usually more efficient than Grid Search because it doesn’t exhaustively test every combination, making it faster, especially for larger datasets.
- Scalability: It works better for high-dimensional search spaces. Unlike Grid Search, Random Search doesn’t need to test every combination, so it’s less computationally expensive as the number of hyperparameters increases.
- Suitable for Large Models: Random Search often finds reasonable solutions faster than Grid Search when working with complex models or large datasets.
Disadvantages of Random Search
- Less Exhaustive: Random Search doesn’t explore every possible combination so it might miss the optimal hyperparameters.
- Requires More Trials: Random Search might need more iterations than Grid Search to find the best set of hyperparameters to compensate for the search’s randomness.
Grid Search vs. Random Search: Which One Should You Use?
Grid Search and Random Search have benefits, and the choice between them depends mainly on the specific problem and the available resources.
When to Use Grid Search
Grid Search is ideal when:
- You have a small search space with few hyperparameters.
- You need a comprehensive, exhaustive search to find the best combination.
- The computational cost is not a significant concern.
When to Use Random Search
Random Search is better when:
- You have an ample search space with many hyperparameters.
- You want a faster, more efficient way to find reasonable solutions.
- You are working with large models and datasets.
Combining Grid Search and Random Search
Sometimes, combining both techniques can be beneficial. For example, you could quickly use Random Search to find a suitable region in the hyperparameter space and then use Grid Search to fine-tune the values within that region for optimal results. This hybrid approach helps you balance speed and precision.
Conclusion: Improving Model Performance with Hyperparameter Tuning
Hyperparameter tuning is essential in machine learning to ensure a model performs optimally. Factors like the nature of your dataset, model complexity, and the available computational resources influence the decision to use Grid Search or Random Search. For those pursuing a data science course or considering a data science course in Mumbai, mastering these tuning techniques will enable you to optimize your models more effectively and achieve better results.
With machine learning’s growing importance in industries worldwide, understanding how to fine-tune models is critical. Hyperparameter tuning improves a model’s performance and helps avoid common pitfalls like overfitting or underfitting, making it a vital part of any data scientist’s toolkit. Whether you’re working on predictive models or deep learning networks, knowing how to apply Grid Search or Random Search will put you on the right path to creating more accurate, reliable models.
Business Name: ExcelR- Data Science, Data Analytics, Business Analyst Course Training Mumbai
Address: Unit no. 302, 03rd Floor, Ashok Premises, Old Nagardas Rd, Nicolas Wadi Rd, Mogra Village, Gundavali Gaothan, Andheri E, Mumbai, Maharashtra 400069, Phone: 09108238354, Email: enquiry@excelr.com.